Sirius-3 DQN-Based AI Agent for Adaptive Threat Detection and Defense (in Minecraft)
Project summary:
In this project, our goal is to let agent protect villagers and kill zombies. We do this by using deep reinforcement learning, which is a combination of deep learning and reinforcement learning. By randomly choosing actions at the beginning, agent will learn from the algorithm and start to choose the best action or move it should do to accomplish our goal.
Approach:
Following is the whole process diagram of our algorithm:
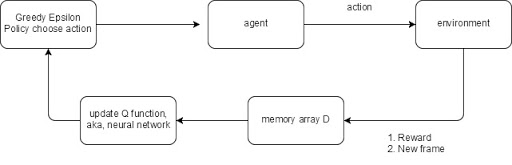
Fig1. Diagram of the algorithm
Algorithm:
To be specific, we use DQN(Deep Q-Network) as our main algorithm. The key point of this algorithm is to fit the original q-value function by using a neural network, which is:
Q(s,a,w)~q(s,a)
where Q is the neural network, w is the weight. We actually design two ways of representing the relationship between state,action and q-values, which will make easier for us to calculate. They are: 1.Q(state)=actions,q-values 2.Q(state,action)=q-value The first one is the actions and corresponding q-values under given state, and the second one is the q-value under given state and action.
In the original Q-Network algorithm, we use Bellman equation to iteratively updating the q-function:
qnew(s,a)= Es’[reward+γ*max q(s’,a’) St=s, At=a]
But apparently, if we already know what q(s,a) is, there is no need for us to use neural network to fit it. Plus, as a traditional machine learning algorithm, the neural network need a loss function to update the weight. Then how do we accomplish these two missions? We use following:
Loss = (reward+γ*max Q(s’,a’,w)-Q(s,a,w))2
Also, if we update w every frame, the value would become very unstable. Because while Q is having a new w, Q’ is also having a new value, which the model would not be able to aim for a correct target. So we update the w every 10000 frame.
Input:
Our input state would be a 5x5 map from every frame, including the position of the agent, zombie and villager. And some direction information of the agent. Different position of either agent, villager and zombie would be a unique position state. The total position states in 5x5 map would be 25x24x23 = 13800. While the agent have degree as direction information, the actual state would be hard to calculate. And that’s why we choose neural network to process. To have more details, we actually take 4 frames as a complete state. Aka, a complete state would be a 4x5x5 array. Because the difference between every frame is too small, especially the position information, any of the unit on the map may be in the same brick for 3~5 frames.
Dealing with Data:
In the traditional machine learning process, we shuffle the data to solve the problem of correlation. Aka, if you are doing a classification problem, it’s better to train some Class A and some Class B, instead of training the algorithm with all Class A and then all Class B. Then we face another problem when we processing the data in DQN: There is no way for us to get future state(data) before we start training the neural network. How do we do that?
We use a experience/memory array to record all the state. We use this array to store the past state, and randomly take out some samples and feed them to the neural network to do the training.
The real memory array would be in the form of:
[frame, action, reward, is_terminal]
We will record every frame, its corresponding action, reward and if this frame is a terminal frame.
Every time we need to take out the data, we randomly choose one frame. The chosen frame we call it “key frame”. The key frame will form a state (frame k-3 to frame k) and new_state(k-2 to k+1). The action will just be the action from the key frame k.
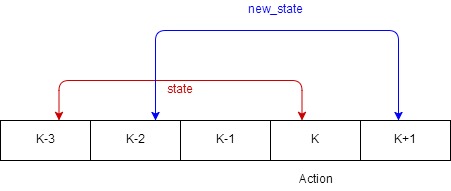
Fig2. How we choose frame
So every piece of data took out from the memory array would be in the form of:
[state ,action, reward, new_state, is_terminal]
We feed the neural network with a batch of above kind of data.
We also consider the storage. Our memory array have a limitation. If it’s full, the new state will replace the old ones. The reason why we doing this is the training could take a long time, and the storage of the RAM could be full. We don’t want the training stops because there is no memory on the hardware.
Reward:
We set 6 different situations for rewarding in total. If villager alive in every frame, we give reward 0.02. If villager died, the agent will have reward -50. If zombie died, it scores 40. If the zombie is attacked by the agent, everytime it scores 10. If agent is attacked by zombie, it scores -5. Finally if our agent died, it scores -40.
Action and Policy:
We only have 5 action, which are move forward, move backward, turn left, turn right and doing nothing. We let the agent keep attacking so that it only need to consider about which way to go. The algorithm we use to choose action is the Greedy Epsilon Policy. We would set the value of epsilon to be 0.05. Then we will randomly generate a number between 0-1, if the number is greater and equal than 0.05, our agent will pick the most valuable action from the q-value list. Otherwise, agent will randomly pick an action to execute.
Evaluation:
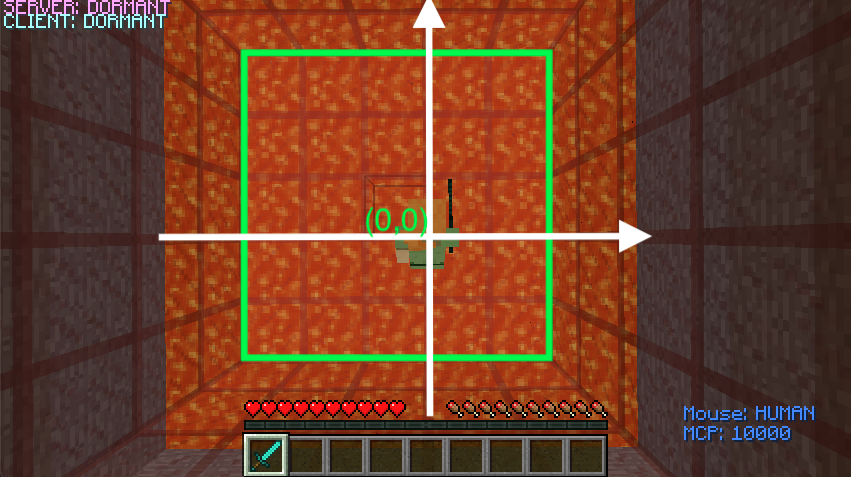
Fig3. Initialize the arena prototype with the coordinates
By setting up our initial map with a 5 x 5 (or 25 blocks) size arena, we are able to train the agent’s ability to observe its surrounding, make an action according to the constraints/score, and learn the reward/consequence of attacking a certain entity. In order to ensure accurate observation, it is necessary to include coordinates that locates each entity (Agent, Villager, Zombie) and differentiates their standing positions (25 blocks). The accuracy is the number of “correct” actions that generates positive reward each mission over the total number of observations. Since our project mainly focus on the reward policy. The performance of this project is measured by how accurately our agent observes its surrounding environment. After we finish training our agent for certain number of rounds, we are able to see that our agent can identify and attack the zombie.
There are some examples regarding our accuracy measurement.
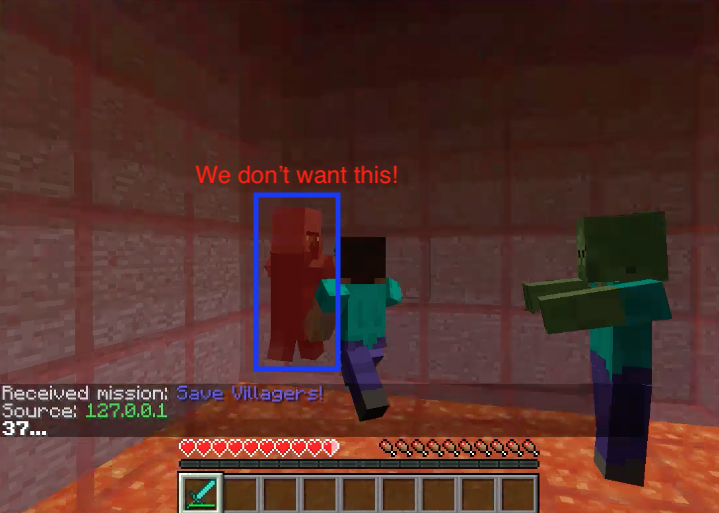
Fig4. The agent attacked the villager
In the picture above, the agent performed an action we don’t want. We count this as a false positive because the agent is able to learn that attacking villager will result in a negative reward. There are also cases when villagers and zombies stayed very close. By which I mean agent may accidentally attack the villager while his first intention was the zombie.
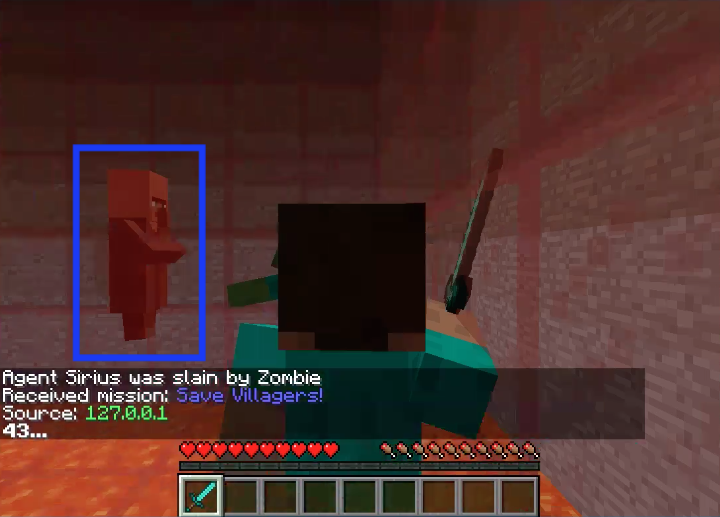
Fig5. The villager was attacked by zombie
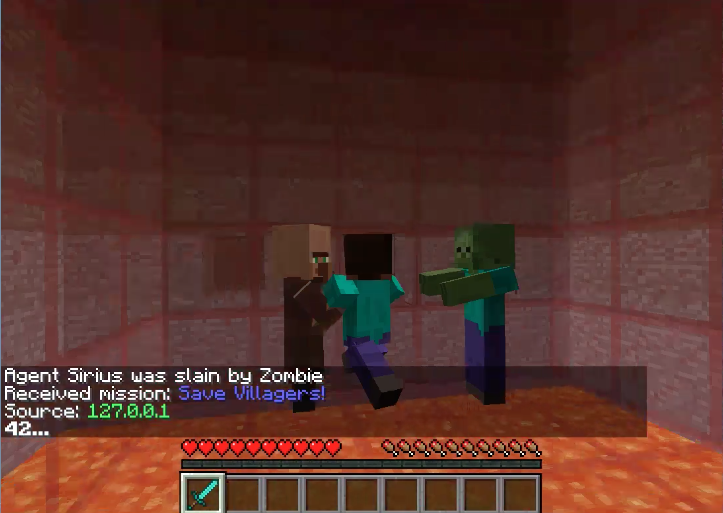
Fig6. Agent draws the attention of zombie
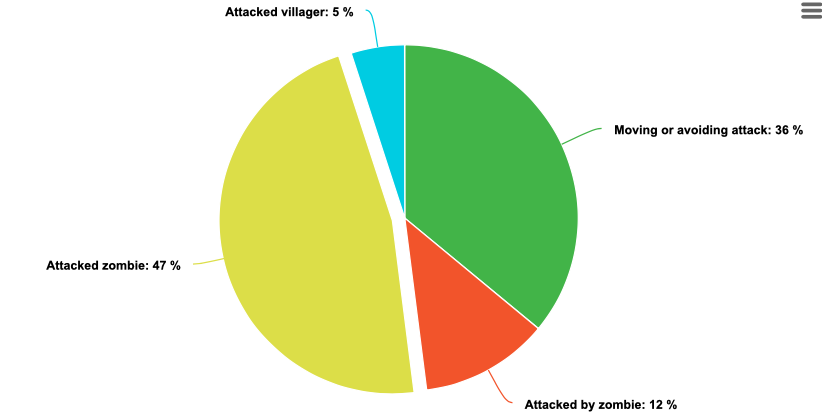
Fig7. Agent’s behavior before training
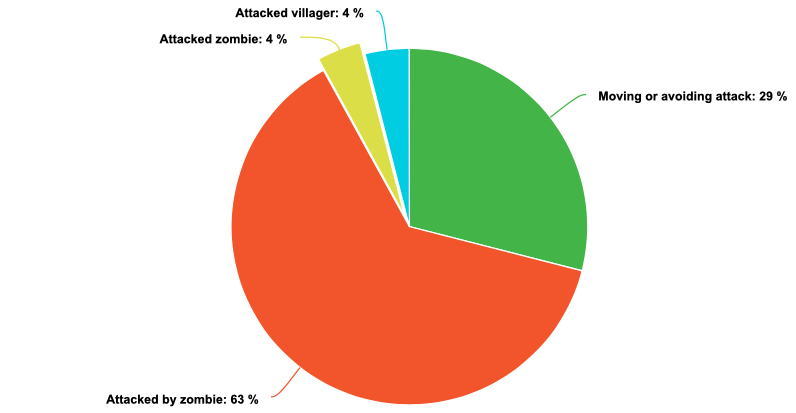
Fig8. Agent’s behavior after training
Table. 5 x 5 [one zombie/one villager] map
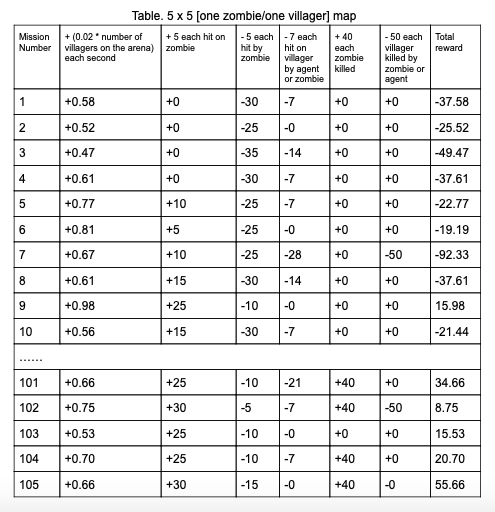
Remaining goals and challenges:
Goals:
- We plan to use Linear Decay Greedy Epsilon Policy instead of Greedy Epsilon Policy. The epsilon value will be set to 1 at the beginning. Since at the beginning process, our q-network does not generate or form a meaningful data set. Besides, the weight value for the neural network is set by random numbers. Therefore it does not necessary to pick an action based heavily on q-value generated by neural network. We will decrease the value of epsilon along with the time lapses. Finally goal is to decrease epsilon value to 0.05.
- We may want to update DQN to Dueling Network. We will separate the state and action. In this way we will have two different value to get a q-network, one will evaluate the value of each state, and the another one will only evaluate the value of each action. Currently, we consider both states and actions together in one q-network which may have the chance that ignore some points.
- When we pick the data from our memory array, we want those data that has more loss than other data to have a higher priority to be picken from the array. Just randomly choose the data from the array cannot tell which data has more value.
Challenges:
- The challenges we encountered is the size of map. So far we can only train our agent on 5x5 grid. Once the grid becomes larger like 10x10 grid, it would take around 10 hours to train. Since the total states will increase with increase of the map. We plan to increase the size of grid little by little, and borrow a computer with a high performance GPU. Or maybe we can do screenshot as input state instead of giving map to the agent since the screenshot has more information, and using CNN would be a perfect match for it.
- We do spend lots of time trying to understand the DQN algorithm, and the experience/memory array. We tried our best to transform the algorithm to the code and we did lots of debuggings.
- The setup of the game was also painful for us. There are lots of unexpected elements we had not considered before, like the angle agent turns. In some angle, agent cannot hit the zombie but zombie can hit agent. Because we have limited information for the agent, it’s hard for it to make adjustion on such kind of situation.
Video Summary:
Resource used:
- Fighting Zombies in Minecraft With Deep Reinforcement Learning - Hiroto Udagawa, Tarun Narasimhan, Shim-Young Lee
- Beat Atari with Deep Reinforcement Learning! - Adrien Lucas Ecoffet
- Playing Atari with Deep Reinforcement Learning - Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra Martin Riedmiller
- XML Schema Documentation
- MalmoPython.AgentHost() documentation