Sirius-3 DQN-Based AI Agent for Adaptive Threat Detection and Defense (in Minecraft)
Approach:
Following is the whole process diagram of our algorithm:
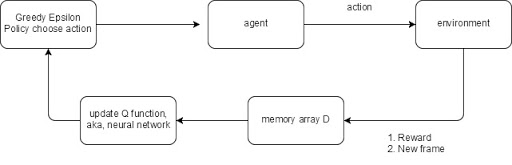
Fig1. Diagram of the algorithm
Algorithm:
To be specific, we use DQN(Deep Q-Network) as our baseline algorithm.
The key point of this algorithm is to fit the original q-value function by using a neural network, which is:
Q(s,a,w)~q(s,a)
where Q is the neural network, w is the weight.
We actually design two ways of representing the relationship between state,action and q-values, which will make easier for us to calculate.
They are:
- Q(state) = actions,q - values
- Q(state, action) = q - value
The first one is the actions and corresponding q-values under given state, and the second one is the q-value under given state and action.
In the original Q-Network algorithm, we use Bellman equation to iteratively updating the q-function:
qnew(s,a)= Es’[reward+γ*max q(s’,a’) St=s, At=a]
But apparently, if we already know what q(s,a) is, there is no need for us to use neural network to fit it. Plus, as a traditional machine learning algorithm, the neural network need a loss function to update the weight. Then how do we accomplish these two missions? We use following:
Loss = (reward+γ*max Q(s’,a’,w’)-Q(s,a,w))2
This means, we use past neural network to fit the future neural network.
Also, if we update w every frame, the value would become very unstable. Because while Q is having a new w, Q’ is also having a new value, which the model would not be able to aim for a correct target. So we update the w every 10000 frame. This is called delayed update policy.We keep the same neural network, but we have two weights.
Our improved algorithm is Double DQN.
Compared with DQN, Double DQN keeps the advantages of DQN and have some improvements. Technically, it’s better than DQN so we don’t talk about the disadvantage of Double DQN compared to DQN.
Double DQN comes from the idea of Double Q-learning. In Double Q-learning, we construct two q-functions and update them alternately, which means if we use Q1 to choose action, we update Q2, and vice-versa. We can do the same in DQN. But we find that, since we are using delayed update policy, we aleady have two weights, we can consider them as two seperate neural network. We don’t need to construct a new one.
So the Loss function of Double DQN is the following:
Loss = (reward+γ*Q(s’,argmax Q(s’,a’,w),w’)-Q(s,a,w))2
We use past weight to choose action, and use this action and new state to fit future weight.
The best improvement of Double DQN is, it elimates the overestimate. In fact, the q-value in DQN would become larger and larger eventually. By doing this in Double-DQN, the overestimate can be controlled so that the q-value won’t become too large.
Input:
Initially, the baseline for our input state would be a 5x5 map from every frame, including the position of the agent, zombie and villager. We use game API to get the yaw infomation of the agent, and we use this to calculate what angle the agent is facing at each frame, since agent need to know where is the enemy and which direction he should go. But we don’t care the angle of the villager and the zombie.
Different positions of either agent, villager and zombie would be a unique position state. The total position states in 5x5 map would be 25x24x23 = 13800. While the agent have degree as direction information, the actual state would be hard to calculate. And that’s why we choose neural network to process.
While in our final version, we make the map become 7x7.
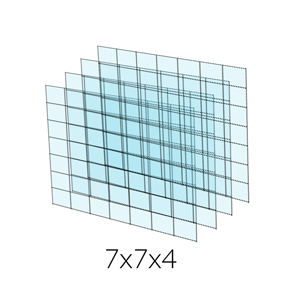
Fig2. Structure of a single complete State
To have more details, we actually take 4 frames as a complete state. Aka, a complete state would be a 7x7x4 array. Because the difference between every frame is too small, especially the position information, any of the unit on the map may be in the same brick for 3~5 frames. So we put 4 frames together to make a status.
Dealing with Data:
In the traditional machine learning process, we shuffle the data to solve the problem of correlation. Aka, if you are doing a classification problem, it’s better to train some Class A and some Class B, instead of training the algorithm with all Class A and then all Class B. Then we face another problem when we processing the data in DQN: There is no way for us to get future state(data) before we start training the neural network. How do we do that?
We use a experience/memory array to record all the states. We use this array to store the past state, and randomly take out some samples and feed them to the neural network to do the training.
The real memory array would be in the form of:
[frame, action, reward, is_terminal]
We will record every frame, its corresponding action, reward and if this frame is a terminal frame.
Every time we need to take out the data, we randomly choose one frame. The chosen frame we call it “key frame”. The key frame will form a state (frame k-3 to frame k) and new_state(k-2 to k+1). The action will just be the action from the key frame k.
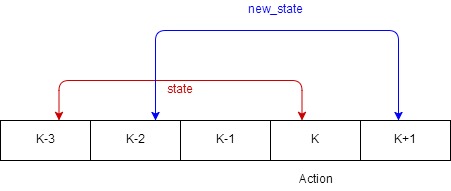
Fig3. How we choose frame
So every piece of data took out from the memory array would be in the form of:
[state ,action, reward, new_state, is_terminal]
We feed the neural network with a batch of above kind of data.
We also consider the storage. Our memory array have a limitation. If it’s full, the new state will replace the old ones. The reason why we doing this is the training could take a long time, and the storage of the RAM could be full. We don’t want the training stops because there is no memory on the hardware.
Reward:
We initially set 6 different situations for rewarding in total. If villager alive in every frame, we give reward 0.02. If villager died, the agent will have reward -50. If zombie died, it scores 40. If the zombie is attacked by the agent, everytime it scores 10. If agent is attacked by zombie, it scores -5. Finally if our agent died, it scores -40.
But in the final version, we delete the reward for the alive of villager, which gets 0.02 every frame. We find that if we do this, the agent may just walk around and buy more time, which would greatly increase the total reward but not killing zombie.
Action and Policy:
Action:
We only have 5 action, which are move forward, move backward, turn left, turn right and doing nothing. We let the agent keep attacking so that it only need to consider about which way to go.
Policy:
We set three policies in our function and use parameter to choose which one we want to use.
1. Greedy Epsilon Policy:
In the baseline, the way we choose action is the Greedy Epsilon Policy. We would set the value of epsilon to be 0.05. Then we will randomly generate a number between 0-1, if the number is greater and equal than 0.05, our agent will pick the most valuable action from the q-value list. Otherwise, agent will randomly pick an action to execute.
2. Linear Greedy Epsilon Policy:
In the final version, we improve the policy to be Linear Greedy Epsilon Policy. The reason we do this is - in fact, all the weights in the neural network are set randomly, so the “best action” it choose makes no sense at all, there is no way that we can trust our model at the begining, so there is no need for us to ask it. Just pick a random action. So at the begining, epsilon is set to 1. With the time past, epsilon would going down little by little until 0.05. By doing this, we start to give more trust to our model with the time pass by, but we still want the agent has the chance to get new/random action.
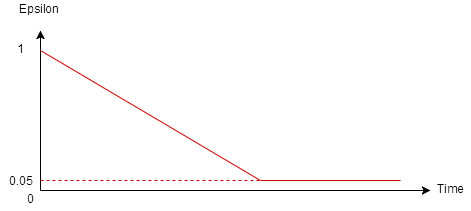
Fig4. Linear Greedy Epsilon Policy
3. Greedy Policy
This policy is totally for testing, we do not set any epsilon. After the model has been trained, we totally let the model decides the best action because we give 100 percent trust for our model.
Evaluation:
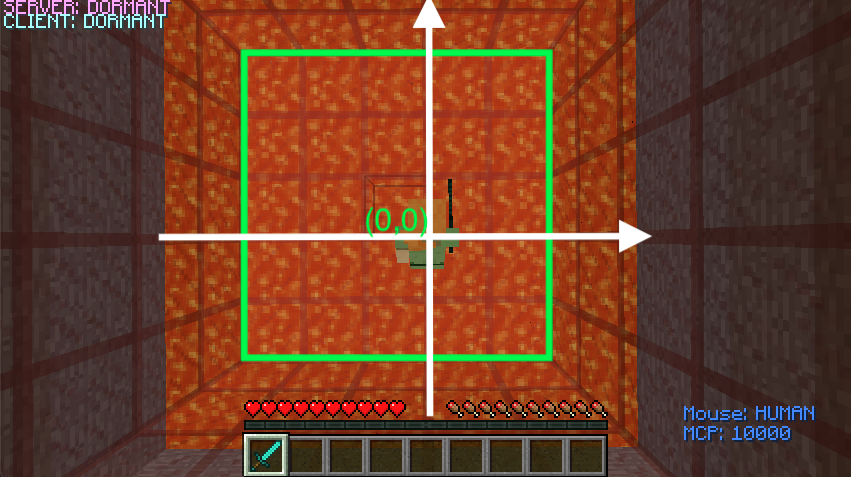
Fig5. Initialize the arena prototype with the coordinates
Baseline
By setting up our initial map with a 5 x 5 (or 25 blocks) size arena, we are able to train the agent’s ability to observe its surrounding, make an action according to the constraints/score, and learn the reward/consequence of attacking a certain entity. In order to ensure accurate observation, it is necessary to include coordinates that locates each entity (Agent, Villager, Zombie) and differentiates their standing positions (25 blocks). The accuracy is the number of “correct” actions that generates positive reward each mission over the total number of observations. Since our project mainly focus on the reward policy. The performance of this project is measured by how accurately our agent observes its surrounding environment. After we finish training our agent for certain number of rounds, we are able to see that our agent can identify and attack the zombie.
There are some examples regarding our accuracy measurement.
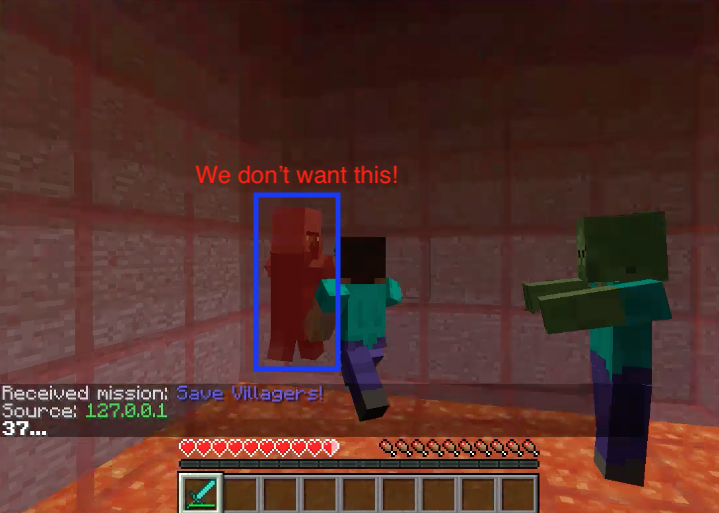
Fig4. The agent attacked the villager
In the picture above, the agent performed an action we don’t want. We count this as a false positive because the agent is able to learn that attacking villager will result in a negative reward. There are also cases when villagers and zombies stayed very close. By which I mean agent may accidentally attack the villager while his first intention was the zombie.
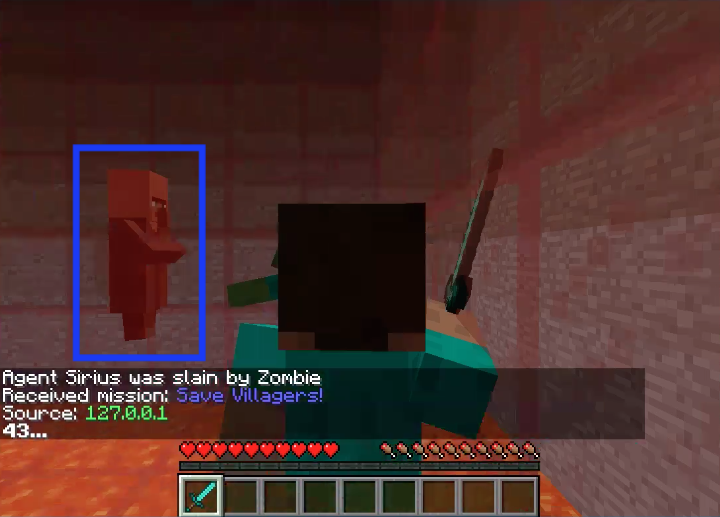
Fig5. The villager was attacked by zombie
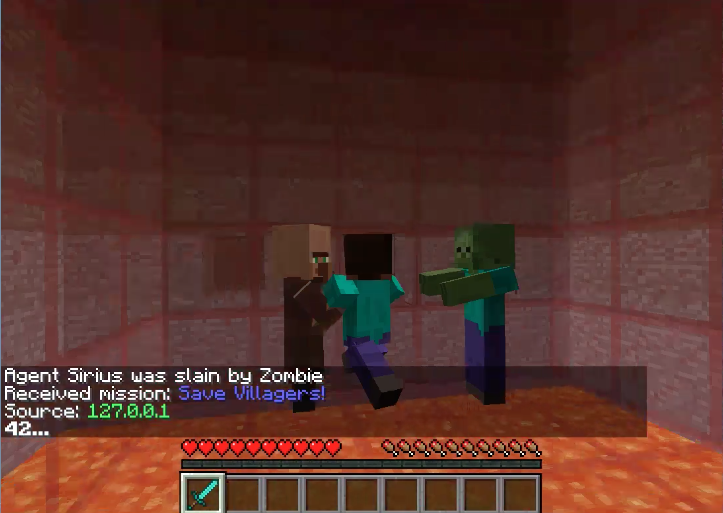
Fig6. Agent draws the attention of zombie
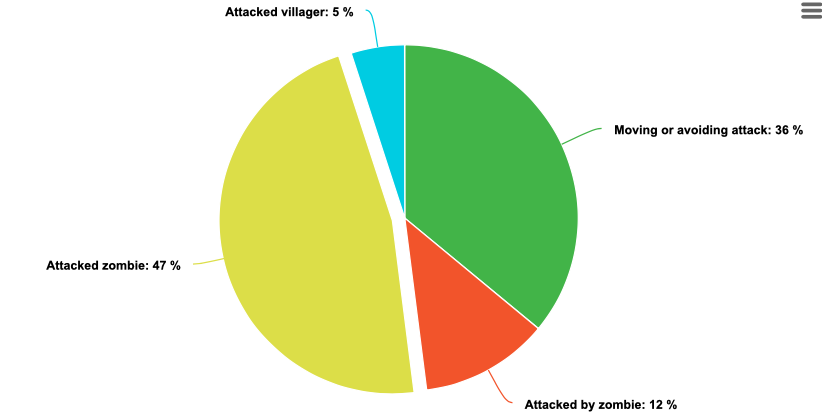
Fig7. Agent’s behavior before training
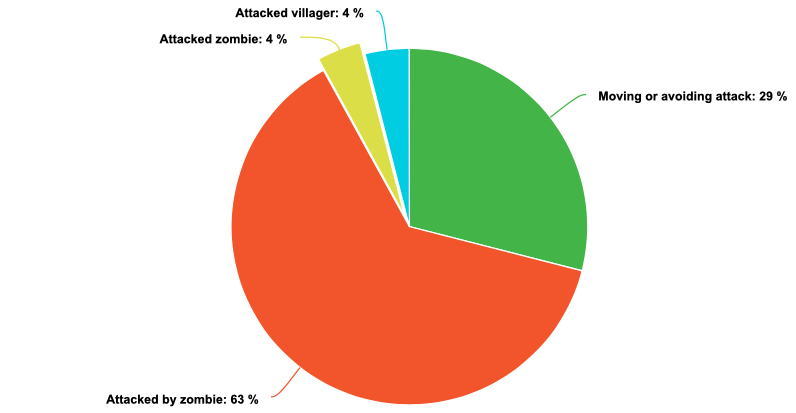
Fig8. Agent’s behavior after training
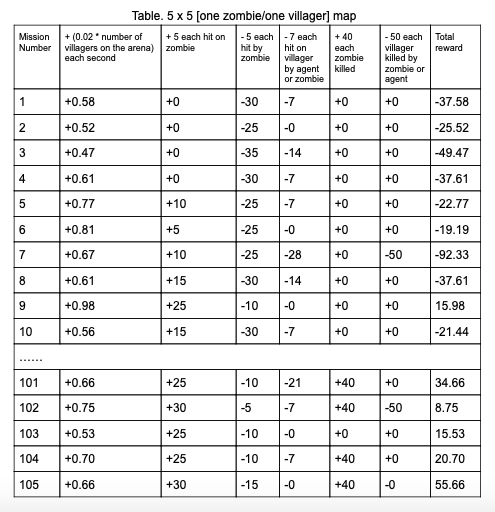 Table. 5 x 5 [one zombie/one villager] map
Table. 5 x 5 [one zombie/one villager] map
In the second phase, we change the prototype of the matrix from containing both positive and negative coordinates to containing all positive coordinates. So that we can easily expand our map size to 7 x 7, 10 x 10 or even larger in the future without changing the core implementation of the helper functions and DQN algorithms.
Final Version

Fig11. Initialize the arena prototype with the coordinates with 7x7
As we setting up a larger map (7 x 7 this time) in order to increase the difficulty of the game since the number of parameter doubles and the agent will need more time/rounds to learn. The data below indicates the learning progress of the agent, you can see the first column represents the total rewards received and second last column represents the number of zombies killed. In this case, a 1 would simply mean “Sucess”. As the training goes on (I neglect the trivial middle training data), we can see the agent is making good progress from round 160 since the agent is able to kill the zombie more frequently than the first 20 rounds. Finally, at about 400 rounds, we can observe that the agent has made steady progress by consecutively slain the zombie.
Table. 7 x 7 [one zombie/one villager] map
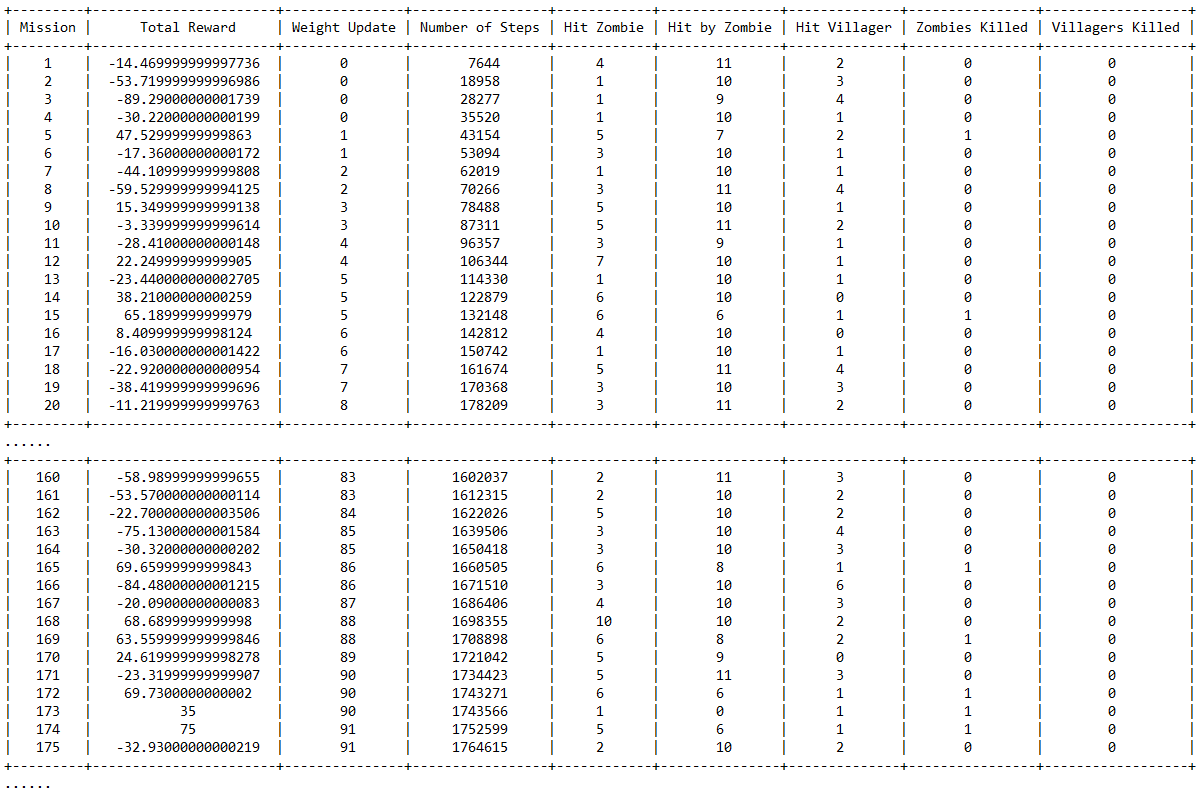
We also test it in the 10 x 10 map, the agent is able to consecutively kill the zombie at approximately 1400 round. The training took about 10 hours and the data is a lot longer, therefore it wasn’t shown here.
Resource used:
- Fighting Zombies in Minecraft With Deep Reinforcement Learning - Hiroto Udagawa, Tarun Narasimhan, Shim-Young Lee
- Beat Atari with Deep Reinforcement Learning! - Adrien Lucas Ecoffet
- Playing Atari with Deep Reinforcement Learning - Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra Martin Riedmiller
- Deep Reinforcement Learning with Double Q-learning - Hado van Hasselt, Arthur Guez, David Silver
- XML Schema Documentation
- MalmoPython.AgentHost() documentation